

Partner to Retail: Automating the Service Transfer Process
Partner to Retail Transfers
After nearly 21 years in business, we have seen just about everything, from partners dying to companies disappearing overnight. More often than not, they leave businesses they served stranded and ExchangeDefender has to pick up the pieces. As each case is different, we’ve always handled every issue delicately with great care from a dedicated employee at ExchangeDefender to handle the issue.
While that sounds nice on the surface, it’s actually a horrific mess with a point person playing coordinator, negotiator, project manager, liason, unofficial legal advisor and more often than not wasting more time than neccessary.
As a result, there is now a 3 month initiative at ExchangeDefender to streamline and automate most of our processes that involve external parties. The honor of the first such automated process is the “Transfer of Services”:
Transfer of Service
ExchangeDefender is exclusively sold through our IT Solution Partners. However, when one partner disappears (death, bankruptcy, laziness, poor customer service) we do not have the means to refer them to a new partner. Often, even if we can find someone local, partner may not have an incentive or business case to sell them ExchangeDefender if the client will not sign up for other support services that are required by our partners to deliver XD. Sometimes, clients get bought/sold, hire their own IT staff, or move to a new provider and want to keep ExchangeDefender. All of these scenarios create a massive mess for ExchangeDefender, for the client, and ultimately for the partner.
The site is designed to create a process-oriented survey that ties in all the parties involved in service delivery – the client requesting the transfer, the existing partner, and if applicable the new IT Solution Provider. This way we have the contact information about everyone, we have set milestones in the process, we have everyone moving along the project and we have deadlines so nobody is left stuck or forgotten. The same ExchangeDefender SLA for support applies to the transfer process but it makes ExchangeDefender handle it.
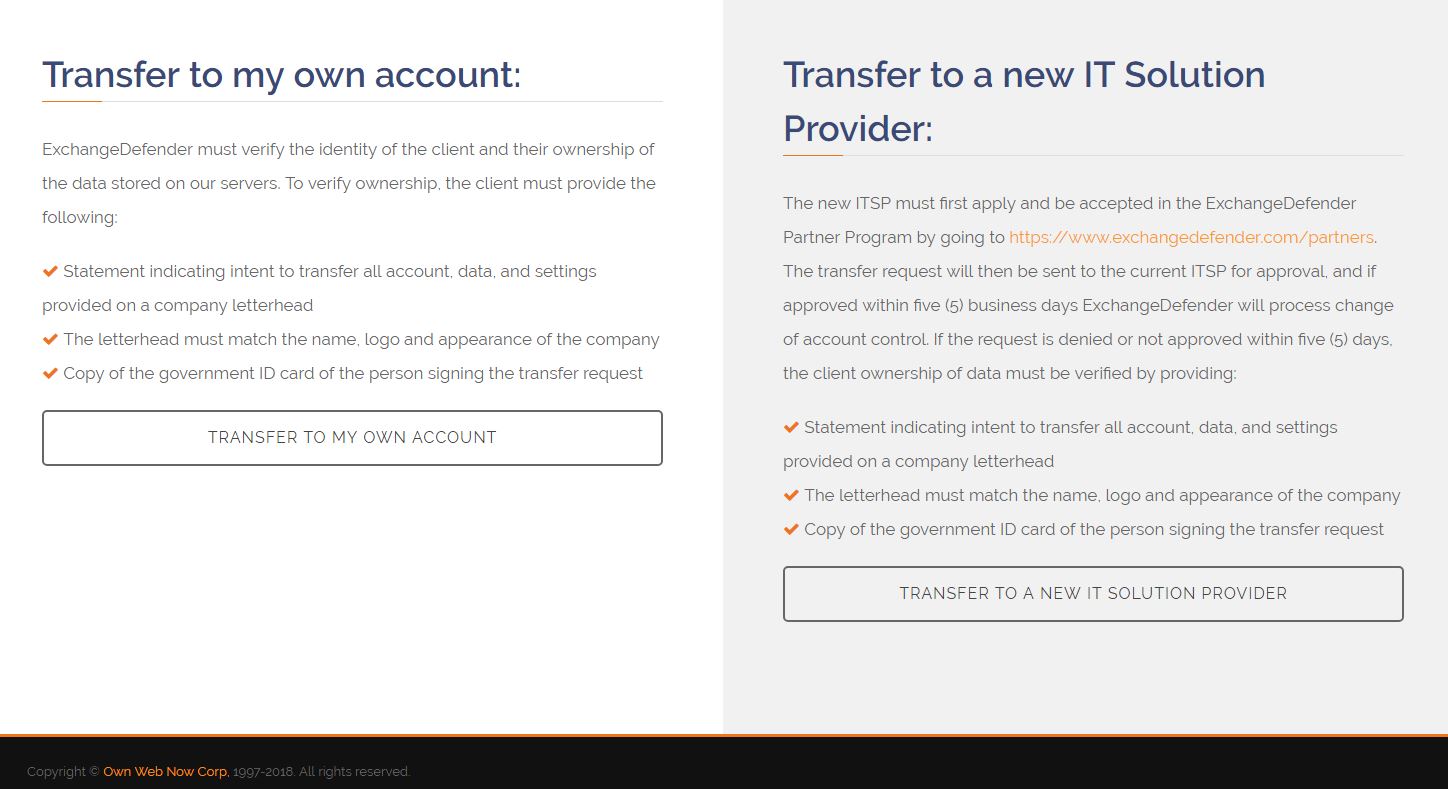
That is the key part and perhaps the most valuable one for our existing partners that may be worried about account transfers. From our experience, when a client decides they want to leave the service (be it ours, or our partners) there is little that will stand in their way of either moving to another ExchangeDefender partner or another service. This can be painful, awkward, and at times emotional as a loss of business can be stressful. This is where ExchangeDefender can help as well – instead of having to deal with asset control, configuration, transferring credentials and doing support and the work of the new IT Service Provider, our partner can just sign a waiver and from that point on anything regarding the old client and ExchangeDefender will be handled by our team. This way the current partner that is losing the service isn’t stuck with an uncomfortable process of dealing with a client that fired them or training their competitor how to manage the service – it’s simply all on us.
We had to do something. All our future transfers will happen through the “Partner To Retail” web site at https://exchangedefender.com/transfer
Our mantra remains the same, we are still very much a partner-channel based organization. These process automation projects are meant to give our partners and clients a more predictable, measurable, and accountable system backed by an SLA rather than a single point person. If there are processes that you’ve found frustrating, unpredictable, difficult, or frustrating please let us know by contacting your account manager and we’ll put some priority on those. Otherwise, we look forward to serving you better.
ExchangeDefender’s New PIN Retrieval Process

About the PIN requests
Several years ago we introduced the ExchangeDefender Phone PIN support to enable our clients and partners to obtain full support over the phone as if they were in our support portal. Being able to talk to someone that can directly make any change you need to make on the go is incredibly valuable for on-the-go business manager that is typical in SMB.
Our implementation left a lot to be desired. We put the PIN in the area where few people looked. We had no system to quickly retrieve your PIN. Some of our support techs took advantage of the system to avoid helping clients. All these issues have been addressed so we wanted to go over our phone support process again.
Our Support Process
We have a typical 3 tier support system – people on the phones (Level 1), people in the support portal (Level 2), and people managing network services and software that approve overrides and make changes manually (Level 3).
When you call 877-546-0316, you will always be speaking to a Level 1 person. Their job is to be friendly and help you figure out how to get things done. In general, they will walk you through the portal, provide our manuals and walk through guides, open a ticket on your behalf, and sometimes even provide additional information about services. Their goal is to eliminate the clutter, the transfers, the “not my department, not my job” you often get when you call a company for help.
If you call our support and are active, in good standing (no late or past due invoices), with proper credentials – our team will greet you with “Thank you for calling ExchangeDefender, whom do I have the pleasure of speaking” and will try to locate your profile and your PIN. From there, we’ll take good care of you. If you don’t know your pin, or if we cannot locate you in the portal, our support will still provide basic public information about our services but is prohibited from discussing pricing, settings, passwords, company data and so on. This is for your security and protection – we’ve all experienced identity theft, people pretending to be someone else, people that have been terminated looking to sabotage their employer, etc – the PIN removes that from being an issue.
What requires a PIN?
Anything that is not public or available on our web site will require you to provide an email address and a PIN. Things that don’t require a PIN are basic answers about how our products work, where to find documentation, if there are any issues with services at the moment, how to become a partner, marketing collateral requests, etc.
Everything else that is account-confidential will require a PIN, for example:
– Getting a copy of the invoice, pricing information
– Account modification, service change, settings change
– Opening a new support ticket on your behalf
– Adding a new service or subscription
– Modifying service settings (passwords, IP addresses, credentials)
There are only two things that our support on the phone will not do regardless of whether you know your PIN or not: add a new contact to the support portal and delete any service/subscription. For legal, compliance, and past experience reasons that is a red line we cannot cross.
OK so how do I get my PIN?
You can find it in your Contact information at https://support.ownwebnow.com
If you don’t know your PIN or support password, you can request a new PIN at https://exchangedefender.com/pin
If you don’t have a contact in our portal at all, you will be provided with a PDF to provide to whoever manages the ExchangeDefender relationship in your organization.
We hope that as we introduce chat and more phone support you can still get everything you want done much faster and more efficiently – but most of all: securely.
ExchangeDefender 9 – September Update

ExchangeDefender 9 is off to a fantastic start, as mentioned in the previous post we’ll keep you up to date with any new bugs and fixes as we find and fix them here (http://www.exchangedefender.com/blog/2018/08/exchangedefender-9-launch-bugfix/). Great news on that front is that the entire codebase is new and thanks to new development methodology fixes for minor issues won’t take long. Neither will the addition of the new features: which is what we’d like to discuss today.
The following big features are coming in September and we’ll cover them in detail leading up to the release: ExchangeDefender encryption is getting a major upgrade in threaded conversations and ability to include attachments both ways, our support portal will begin mixing in live chat and status updates so you know immediately where your ticket is in our system and who is working on it, and we’re taking a major step forward to help you manage your security credentials.
ExchangeDefender Encryption Upgrade
ExchangeDefender Encryption is getting a major expansion of features when it comes to handling files and conversations. Specifically, we never want you to have to leave the ExchangeDefender web site in order to communicate effectively and securely. Starting in September, we’re adding two major features to enhance our clients ability to exchange secure content with remote recipients: threaded views and attachment uploads.
Presently, only our clients (protected by ExchangeDefender) can send encrypted attachments. Soon, senders and recipients will be able to work through our portal to send encrypted contents back and forth. The way we’ll present the entire conversation will really take our clients productivity to the next level.
Support / Ticket Live Chat
We’ve been testing a live chat/alert/popup functionality in our support portal where we can huddle up and work on the ticket in realtime with the entire team. This is a far cry from the traditional model where a ticket is accepted, assigned, worked on and completed by a single tech within a SLA mandated period of time.
In the new model, we all have the ability to work on every issue at once and quickly add relevant resources to the conversation: which is effectively what the new support is going to look like. So instead of a ticket being a single monolith of a problem that is handed from one person to the next in it’s entirety, we can now break it down into manageable pieces and a senior engineer can quickly pinpoint, triage and offer guidance that would let other technicians that are available assist the client far faster.
You will also be able to see who is viewing and working on your ticket and where/when the next update will come – this will eliminate the need for phone calls, escalation/status update requests and so on because the system is 100% reactive to what is going on – if the engineer is looking at the ticket they have a counter and they are printed on the ticket. We look forward to extending this functionality to our clients in September, we’ve been using it internally to raving reviews by our staff.
Password Policy Enforcement
ExchangeDefender is a security product – one whose origins and some features trace back to the 90s. In the past 15 months the product has been rewritten entirely, giving us far more flexibility to help you manage your users and their passwords. In September we will start storing passwords with irreversible encryption and complying with many new technologies such as Magic Link that will make password tracking a thing of the past. Additionally we’re rolling out 2FA/OTP across ExchangeDefender with our own API to extend to other applications in the ExchangeDefender universe.
There will be many more features coming along as all our departments have stepped their game up – but these major ones will definitely change the way you work with ExchangeDefender and how much we’re able to do for you and your clients. Privacy, security and management are in the news every single night and we hope to give our clients and partners a level of control over their data that will make it easier for them to sleep at night.
ExchangeDefender Support Evolved
It’s crazy to look at the ExchangeDefender roadmap from last spring and see how well we’ve been able to integrate the vision for a fully supported communications platform for business into our existing security, compliance and encryption product suite. To be honest, this whole process started well over a year ago with our ExchangeDefender Migrations where we learned just how poorly organized and borderline mismanaged most corporate email handling has become. And all the tools that are on top of it – from Outlook to supplement chat platforms – are just making the mess bigger and compliance problem more complicated and expensive.
I’ve personally spent countless hours with my staff looking at tons of research, behavioral data, purchase patterns, market leaders (and which features people most demanded from them compared to which features they actually used the most) and that’s where we started building our new platform. And if you’ve attended any of my webinars for the past year or so, you’ve heard me repeatedly call on partners, MSPs, VARs, etc to focus on the messaging, compliance and security because that is where the money has been and will continue to be – and it won’t be something you’ll ever earn with a low end network admin hire (not to mention that we’re better and far more affordable than another body).

I am beyond thankful for all the feedback, input and suggestions (keep them coming, as brutally honest and direct as possible – no, we don’t expect you to be cheerful if/when we cause you support problems) that are pouring in as we start to expand this product. In terms of vision of what we’re building here:
A platform for secure, compliant and organized information management, sharing and collaboration.
If that sounds like a Dilbert cartoon too heavy on jargon, what I mean is that we’re launching a series of web sites, mobile apps, web applications and automation scripts that any organization out there can plug in their email into and start assigning, prioritizing, discovering and working on issues together. We’re not just talking about b2b or b2c email either, anything that generates an email notification or a social alert or an order receipt or booking confirmation or a tweet or a Facebook update – anything that impacts your business – will be more secure, better organized and have a clear chain of custody, deadline, track record and more.
This is not a one-off upgrade that we’re thankful to be done with, this is just a piece of the overall puzzle we have for our partners to help organizations get better organized. So please, stay in the loop, and most of all understand the game plan: we aren’t building this to amuse ourselves – what you see here will be your product in another month or two and you will be able to sell, implement, customize and manage. And that kind of work pays a lot better than hard drive swapping, OS reinstall and malware license renewals.
We hope you like it. And we hope that if you don’t like it, you tell us what you need. Either way, we won’t do this without you. #team
-Vlad
We need your support feedback
We’ve been getting incredible feedback since the launch of our new support portal but believe me when I say that this is just the preview of what we’ve got going on behind the scenes. As ExchangeDefender’s business model continues to shift towards security and compliance services (instead of just software/cloud) our ability to provide excellent service becomes the top goal organizationally. And it matters the most to you, our clients and partners, because we’re lifting the burden of support and platform management from you so we need to be able to provide support on a whole new level as a result of it.
On the bottom of all the new sections of the portal you will see a link that says [BETA] Give us feedback.

Tap that link and tell us what you would like to see.
I cannot overstress the importance of us getting this right, not just for our own sake but for yours as well: support and assistance will start getting bundled and integrated into the very solutions we provide. This means that we will be using your brand, your logo, your site to deliver ExchangeDefender services on your behalf and that will include realtime communications with clients, employees, staff and anyone else with valid credentials. You will have full control over it all, along with analytics and reporting: we won’t do this without you is more than just a tagline on every webinar I’ve held in the past two years.
So please. Whatever you see, however minor, whatever idea you have, however major: I want to hear it. Developers won’t. I want us to continue providing an integrated cloud service end-to-end that continues to thrill customers instead of frustrating IT people. We’re changing the game here.
-Vlad
Looking for a way to spend less time on email/client support ?
Not growing as fast as you’d like, or spending too much time on email/client support? Hear our CEO’s thoughts on what is fueling our growth and how ESS is already playing a huge part in growth of managed services across our client base.

ExchangeDefender Become a Partner banner
Client Support – Can’t someone else do it?
On February 1st, ExchangeDefender will officially start providing end user support for all email issues related to our platform. For our many partners and resellers this means that we will, under your name and brand, take and place calls and help your clients solve email problems. At no additional cost, across our entire Pro line of services: ExchangeDefender Pro, Exchange Pro, Compliance, and Encryption.
It just makes sense. Our entire service lifecycle is structured around ITIL, integrates into our partners support infrastructure seamlessly, is covered by our SOC1 and SOC2 audits, comes with advanced reporting, security/id, session and call recording… and a lot more that we cannot publicly disclose. But if you join me:
Wednesday, February 7th, Noon Eastern
Click here for the NDA & Instructions
This is going to be one of the denser webinars we’ve ever put together and the audience includes everyone from management down to helpdesk – what I have on deck is a layout of our service model, our scope, our escalation policies, our compliance protocol, authentication and validation service, etc. Consistency in this service is key so winging it or improvising isn’t an option.
-Vlad
P.S. I encourage you to check this thing out live. If you think this will be a service you offer down the road, this webinar (minus the Q&A) will be required viewing and the software will track attentiveness so if you even mildly care, I’d tune in or make someone at the office watch it.
Hosted Exchange – Configuration Checker
Throughout the day we receive hundreds of requests for new services and existing account modifications. Luckily we automated this process from a very early stage and this helped to prevent 99% of account provisioning errors. Believe it or not, there was once a time where everything was processed manually!
However on occasion when there is a hiccup, then it’s simple a matter of locating the source of the issue. While issues on our end are rather easy to diagnose and fix, it’s not always as simple on the partner’s side. There can be a handful of issues that can arise if the account is not properly configured or contains an invalid parameter.
This is why we’ve implemented a well overdue feature integrated directly inside the service manager. If you select the drop down box next to any Hosted Exchange account, you will see a new option called “Check Configuration”.

After selecting this option you will be brought directly to the “Check Configuration” page. It will automatically populate the email address from the previous screen and run the initial check. Also keep in mind that you are able to test other accounts without leaving this page.
It will perform several checks including: Syntax, Server Location, Provisioning, MX Record, Autodiscover and validates that the account is protected by ExchangeDefender. In the event an issue arises you have the option to either “Email” or “Open Ticket” which will automatically include the onscreen results.


We believe that solving the issue promptly makes for a better long term relationship. So if there are any features or adjustments we can make to help smooth the transaction between you and your clients, don’t hesitate to let us know! Our support staff eagerly awaits the opportunity to speak with you about how we can continue to improve our process!
What the VP of Development does at ExchangeDefender
Here at ExchangeDefender we have a wide range of products and service offerings. With close to seven years with ExchangeDefender, I’ve designed and written a majority of the software that is offered as a part of continuously growing platform. This includes several of our key systems such as: Encryption, Compliance Archive, Web Sharing, LocalCloud and even our service ordering & account provisioning! The only areas that I don’t touch directly are mobile applications, we have additional developers who designs and tackles any issues that may arise on our mobile platforms.
Throughout the course of the day I find myself working on various bugs and communicating with our team to ensure that bugs and new feature requests are considered and placed within our internal development pipeline. Recently I’ve been going through our old documentation and working on updating that with fresh information detailing step, by step how to use our products.
Keep in mind that it takes a while to develop and test fixes to assure they don’t introduce other problems. There are no quick fixes or features, everything we implement needs to work well across web, desktop and mobile devices and our support staff needs to be trained and alerted of these upcoming features. So if you have a bug or feature request that is absolutely something that we must fix and/or implement, we would love to hear about it! However, due to my schedule and workload I’m typically a very hard person to reach. So first open a ticket in our portal, our highly trained technicians will review your ticket and possibly collect further information. After which, they will then escalate the ticket into a bug or feature request. Once in this section, it will be reviewed every Friday to see just how we can make our services even better!
Here at ExchangeDefender we want to help you fill your services portfolio with everything your client needs to operate their business successfully. We strive every day to be the absolute best for all of your service needs. So please (I cannot stress this enough) if you think we are falling short due to a software glitch or missing feature, let us know!
Large Scale Migration
 The most important aspect of a large scale migration is communication. This can make a migration that either turns you into a trusted company relationship or the most recent “IT guy” that was fired by that company. There is a delicate balance that you must preserve between the needs of the technology and the needs of the business owner. The best way to do that is to be as meticulous as possible with your communication process.
The most important aspect of a large scale migration is communication. This can make a migration that either turns you into a trusted company relationship or the most recent “IT guy” that was fired by that company. There is a delicate balance that you must preserve between the needs of the technology and the needs of the business owner. The best way to do that is to be as meticulous as possible with your communication process.
Prep work, communicate.
The first thing you must do is map out an initial time line and start testing the process. This time line will start solely based on the IT departments recommendations. These recommendations are generally based on the hardware or support life cycles and the length of time to complete it. Once you have that sorted out, you probably want to add another two weeks to a month of notice and relay that information to the decision makers at the affected company.
Test, communicate.
Once you’ve received a response, you make adjustments as necessary to your schedule and begin a live test where permissible. We also see excellent guides on the internet on how to do any migration imaginable; the most important point to consider is that no two are alike. So you found a frame work to use on the internet, so you have to take the next step. What we typically do is use test mailboxes, we migrate them individually, and then we move them as batches, repeatedly. The bottom line is this; the more work you do before the migration the less likely you will have to pay overtime for a botched migration.
Execute, communicate, then communicate again
Once you’re satisfied, you reach out to your clients again and confirm that you’re ready to start as you previously agreed. This is where the process will vary when dealing with end users versus an IT partner. We can get away with the following notices: an announcement, a reminder, a start, a mid-point, a completion and a couple of follow-ups. We are about to do this due to the fact that we’re dealing with top notch technology professionals. However, with end users you have to have a more controlling approach, depending on the size of the business, you may opt to have everyone come into the office and leave their mobile devices with you for the migration, or you can do appointments. The most important thing in the process is to check as often as your staffing will allow it, that everything is going smoothly and that the expectations you set are being met. I would even advise a follow up call at 1 week and 2 weeks out to pick up the “slow to report issue” folks.